Confidentiality and security are very important to us.
We go through great lengths to ensure that your identity as a participant remains entirely confidential and that there is no information connecting you to your responses on either the social network analysis or the survey. Similarly, we take precautions that no individual’s identity can be deduced from peripheral information in the dataset, such as department or individual connection.
In this document:
- we first give you an overview of how data will be analyzed and could be available in publication or articles.
- We then discuss risks in the data system.
- Finally, we discuss the mechanisms that we use from the time in which you respond to the time in which the final, anonymized data set is created.
- We will identify disciplines by the general field and a random identifiers. These labels will look like Physical Sciences Unit A or Humanities Unit C.
- We may provide network data or sociograms of disciplinary units, but the specific discipline and individuals will never be identified.
- We may provide quantitative measures of the discipline’s network such as network centralization, network density, and average degree. Again, disciplines will be referred to by the general field and the random identfier, such as Physical Sciences Unit A.
- We may analyze individual nodes within a discipline based on measures such as centrality or subnetwork membership. Individual nodes in publication will be identified by a random character string that has no meaningful information encoded.
-
The primary risk comes from the security of your computer and
internet connection:
- If someone has remote access to your computer, they may be able to view your answers as you are making them.
- As with any internet communication, it is possible that someone is intercepting the transmission of your responses to our server and may be able to decipher the information you send. They would not have access to your name, and they would only have access to your participant key if they intercepted the submission of the first page (when you entered it) AND linked that submission to your subsequent responses to the survey pages.
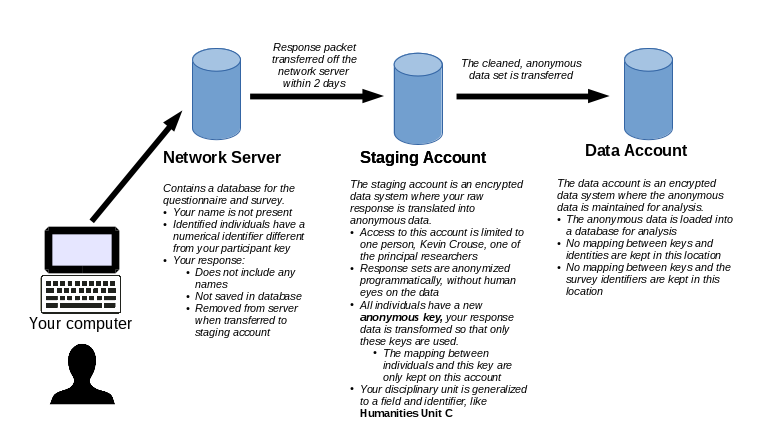
- If someone gains access to the server before your response is moved to the staging location, they may be able to access a data file with the ordinal representations of your responses, the node identifier of the individuals in your network, and your participant key. No names or labels are kept in this file. If this were to happen, it would constitute a significant data breach for our network service provider.
- There is a risk that someone with physical access to the computer on which the data is stored (the staging account, see below) could access the link between names, participant keys, and final identifiers. We minimize this risk by maintaining both the staging account and the final, anonymized datasets in encrypted accounts. However, as the FBI has shown regarding the decryption of the iPhone of the San Bernadino shooter, given enough time and expertise, encyrption can be broken.
- The participant key is randomly generated and never connected to the named individuals (node identifiers) in the server database. This is why you can select your own name as a connection (but please don’t).
- The participant key is only sent to the server when you initially log in, after which a session key is passed between the server and your computer. Someone intercepting a transmission of a single page would receive your session key, but not your participant key.
- The mapping between participant key and your name is not located on the server.
-
Your responses are secured after you submit each page:
- Response information is never kept in the server database, this is why you can’t go back and revise your previous answers.
- The response information cannot be accessed through the web, The response dataset is kept in a private user directory, which is not under the public_html directory.
- Your responses are removed from the network server shortly after you enter them. They are moved to an encrypted user account created solely for this project (the staging account). The staging account is not mounted/accessible on the host computer by default, and so it cannot be accessed accidentally or deliberately by an outsider. Even if an adversarial party had physical access to the computer, it would require sophisticated cryptographic tools to break the account’s encryption.
-
Your responses are transformed and loaded into the anonymized
results dataset:
- The dataset is stored in an encrypted user account created solely for this project (the data account). Like the staging account, the data account is not mounted by default and cannot be accidentally accessed by outsiders even if they had physical access to the computer.
- Files in the staging account are not visible to a user logged into the data account, and vice versa.
- There is no record of the discipline in the results dataset or data account.
- There is no record of the participant key or any individual name in the results dataset or in the data account.
- There is also no record of the node identifiers from the server database in the data account or results dataset.
- In short, what we are trying to say in the last four points is that even if someone had full access to all of the information from the survey and also had all participant keys and somehow figured out their mappings, they could not figure out anything in the final datasets.
- Further, the discipline is generalized in the results dataset; we create a label and identifier to connect the discipline to the general type of research only (e.g., Humanities, Physical Sciences). This is so that it is not possible for someone intimately aware of all of the faculty in a department to deduce identities from the network data.
- In the results dataset, individuals are identified with unique, random character strings that are not connected to either (a) the participant keys or (b) the node identifiers used in the server database. Therefore, a person looking at results could not determine the identity of nodes by looking at the questionnaire OR a new response dataset.
- Because there is no record of the node identifiers in the results dataset, a person with access to the server database or the mapping between connections you selected and their identifiers could not identify those individuals in the results dataset.
The graphic below shows an abbreviated overview of the flow of information and the way data is translated to ensure that identities remain confidential.